UBCO COSC370, BSPlib project: Week 3: Three versions of broadcast
This week you will write you will write three different versions of a broadcast algorithm : naive, logarithmic and 2-phase. The purpose of all these algorithms is the same: one processor (in our case processor 0) holds some data in the form of an array that it will transmit to all other processors.
1 Naive broadcast
The goal is to have processor one holding one array of data (which for the purposes of the exercise we can just generate randomly) to transfer to all other processors. We can do this simply in two supersteps:
- 1) Setup
- Processor 0 generates the data (an array of size N) to be broadcast. All processors must allocate enough memory to store the copy of the data that they will receive. They then use registers so that processor 0 can communicate to the others. They then synchronize.
- 2) Communication
- Processor 0 then loops over the processors ids and sends their
data to each other processor using
bsp_put.
- Processor 0 then loops over the processors ids and sends their
data to each other processor using
Graphically, this can be illustrated thus.
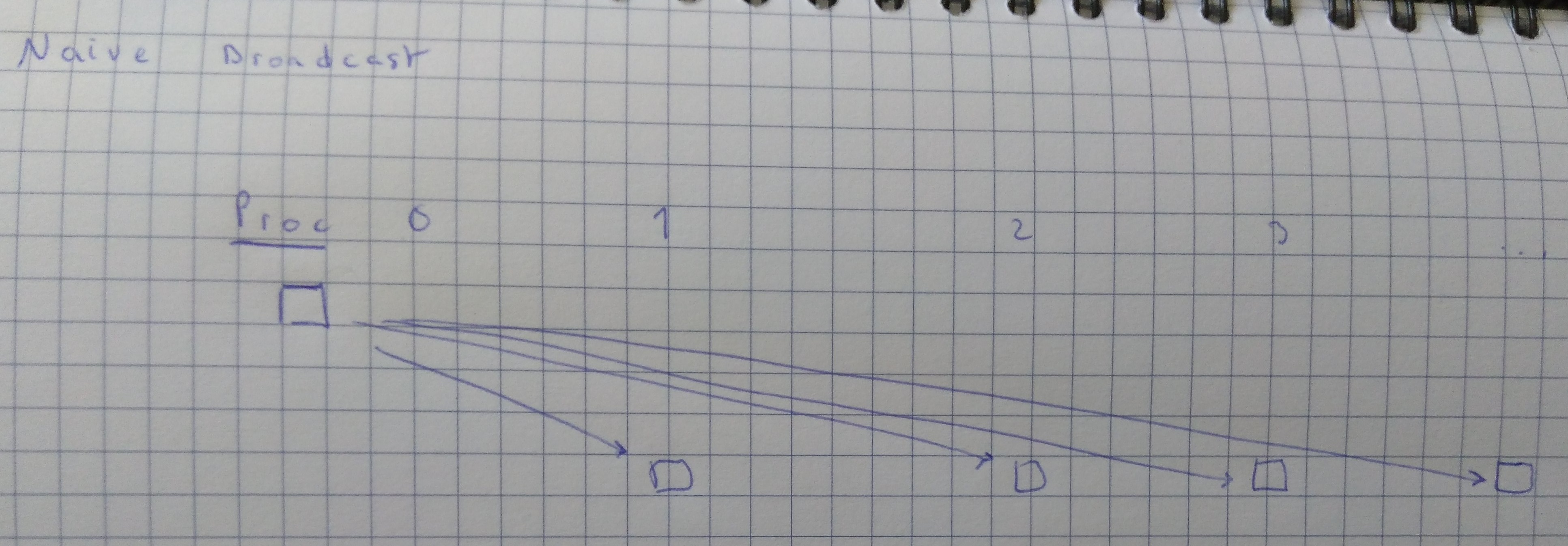
Figure 1: Naive broadcast
Task 1: Implement the above algorithm. How can you verify that the other processors received the correct data in the second superstep?
Task 2: The second step can also be implemented using bsp_get
(man). Try this, it will save you a loop.
Task 3: (optional) What is the communication cost: the maximum number of bytes received or sent by any processor in this program? I.e. If \(S(i)\) and \(R(i)\) is the number of byte sent respectively received by processor \(i\), what is \(max_{i \in \{0..p-1\}} (max(R(i), S(i)))\)?
2 Logarithmic broadcast
The problem with the naive version, which this and the last version tries to solve, is that processor 0 has to do a lot of communication. The idea behind both this and the next version is send out parts of the input array to the other processors and have them communicate it between them-selves.
In the logarithmic version, they do so by creating a tree of communications, of height \(log_2(p)\). To do this, each processor that has received the data sends it to one other processor. In the first superstep, one processor has the data (processor 0) and sends to one other processor. In the second, each of the two processors that has the data sends it to one processor. Thus in the third superstep, 4 processors has the data, and so it continues until all processors have received the data.
In practice, we will implement this by having each processors that has the data (processor \(i\)) send it to the processor with pid \(i + k/2\) where \(k\) is \(p\) initially and halved in each superstep. Here is a graphical illustration:
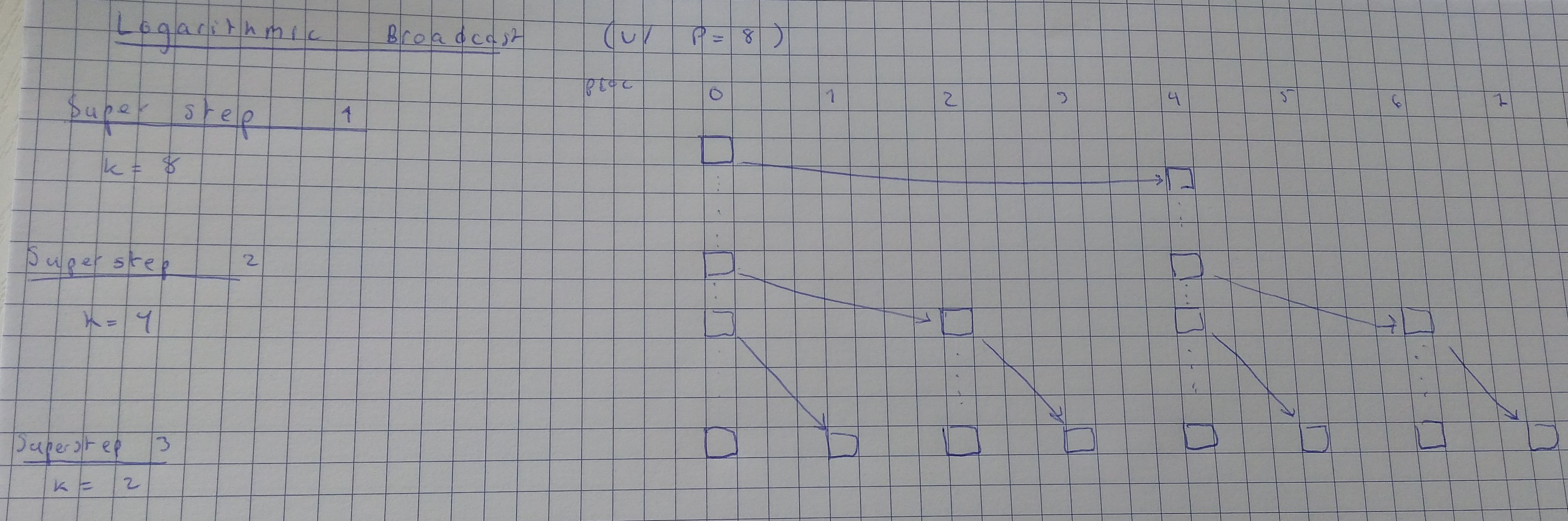
Figure 2: Logarithmic broadcast
The pseudo-code of the algorithm is thus:
// Superstep 1:
// ... all processors allocate space for the data
// ... processor 0 stores something random in data
// ... registers are set up
bsp_sync();
// Superstep 2+:
k = bsp_nprocs();
while (k >= 1) {
// do i have the data already?
if ( ... i have the data already ... ) {
... i send the data to my neighbor k/2 steps to the right ...
}
... half k ...
bsp_sync();
}
Note: this code will only work when the number of processors is a multiple of 2. There are ways around this, but you can just assume that it is the case.
Task 1: Implement the above algorithm. How can you verify that the other processors received the correct data in the second superstep?
Task 2: (Optional) What is the communication cost, i.e., the maximum number of bytes received or sent by any processor in this program (i.e. the same question as in Task 3 for Naive broadcast.) What is the number of synchronizations depending on the number of processors?
Task 3: (Optional) This algorithm can also be implemented with
bsp_get, but in this case there not really any benefits to doing
so. If you're motivated, have a go anyway.
3 Two-phase exchange
In this version, instead of processor 0 transmitting the whole input array at one point, it transmits blocks of it to all other processors. In the first superstep processor 0 divides the input data into \(p\) blocks, and sends one of these blocks to each processor. In the second superstep, all processors sends the blocks they have to the other \(p-1\) processors. In the end, all processors has \(p\) blocks, i.e. the full array.
This is best illustrated by a picture:
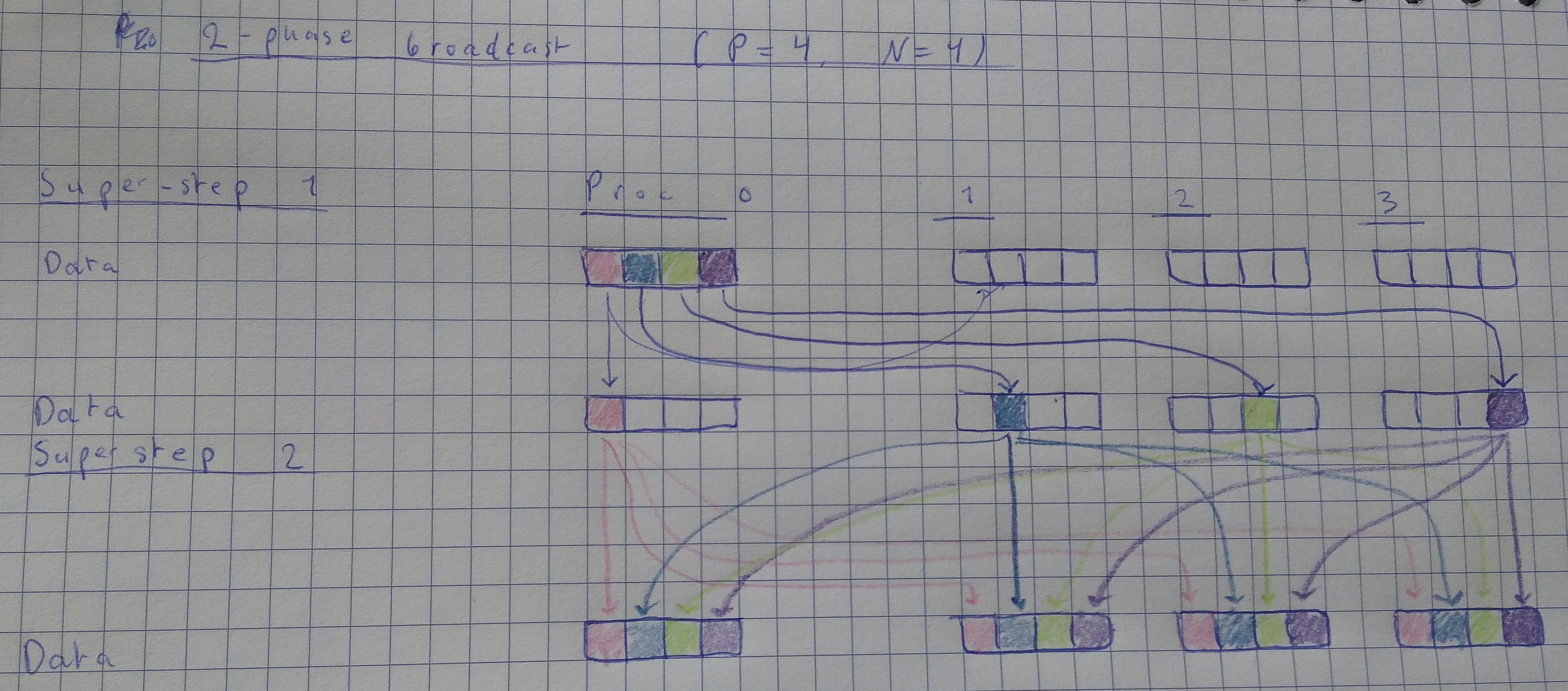
Figure 3: 2-phase broadcast
In Figure 3, there are 4 processors. Each block is represented by one color. In this illustration and in the pseudo-code below, processor 0 will communicate data that it already has to itself. This simplifies the code, and furthermore is treated as a "no-operation" without cost by the BSPlib library.

Figure 4: 2-phase broadcast, alternative illustration. Credit: Gaétan Hains.
Figure 4 contains an alternative illustration.
Note: It is simplest to implement this algorithm when the \(p\) divides \(N\) i.e. when \(N\) is a multiple of \(p\). You can assume that this is the case.
The pseudo-code is then:
// Superstep 0:
// ... all processors allocate space for the data of size N
// ... processor 0 stores something random in data
// ... registers are set up
synchronize
// Superstep 1: First phase
blocksize = N/p
if .. i am processor 0 ...
for each other processor:
send one block of size blocksize to that processor
synchronize
for each other processor:
send the block received in the last superstep to that processor
Task 1: Implement the above algorithm. Hint: use the offset
parameter of bsp_put (man) to put the blocks in the appropriate place in
the data-array at the receiver.
Task 2: (Optional) What is the communication cost, i.e., the maximum number of bytes received or sent by any processor in this program (i.e. the same question as in Task 3 for Naive broadcast.)
Task 3: (Optional) Compare the communication cost of the three algorithms.
–
Back to overview.